Whether you’re a data scientist crunching big data in a distributed cluster, a back-end engineer building scalable microservices, or a front-end developer consuming web APIs, you should understand data serialization. In this comprehensive guide, you’ll move beyond XML and JSON to explore several data formats that you can use to serialize data in Python. You’ll explore them based on their use cases, learning about their distinct categories.
By the end of this tutorial, you’ll have a deep understanding of the many data interchange formats available. You’ll master the ability to persist and transfer stateful objects, effectively making them immortal and transportable through time and space. Finally, you’ll learn to send executable code over the network, unlocking the potential of remote computation and distributed processing.
In this tutorial, you’ll learn how to:
- Choose a suitable data serialization format
- Take snapshots of stateful Python objects
- Send executable code over the wire for distributed processing
- Adopt popular data formats for HTTP message payloads
- Serialize hierarchical, tabular, and other shapes of data
- Employ schemas for validating and evolving the structure of data
To get the most out of this tutorial, you should have a good understanding of object-oriented programming principles, including classes and data classes, as well as type hinting in Python. Additionally, familiarity with the HTTP protocol and Python web frameworks would be a plus. This knowledge will make it easier for you to follow along with the tutorial.
You can download all the code samples accompanying this tutorial by clicking the link below:
Get Your Code: Click here to download the free sample code that shows you how to serialize your data with Python.
Feel free to skip ahead and focus on the part that interests you the most, or buckle up and get ready to catapult your data management skills to a whole new level!
Get an Overview of Data Serialization
Serialization, also known as marshaling, is the process of translating a piece of data into an interim representation that’s suitable for transmission through a network or persistent storage on a medium like an optical disk. Because the serialized form isn’t useful on its own, you’ll eventually want to restore the original data. The inverse operation, which can occur on a remote machine, is called deserialization or unmarshaling.
Note: Although the terms serialization and marshaling are often used interchangeably, they can have slightly different meanings for different people. In some circles, serialization is only concerned with the translation part, while marshaling is also about moving data from one place to another.
The precise meaning of each term depends on whom you ask. For example, Java programmers tend to use the word marshaling in the context of remote method invocation (RMI). In Python, marshaling refers almost exclusively to the format used for storing the compiled bytecode instructions.
Check out the comparison of serialization and marshaling on Wikipedia for more details.
The name serialization implies that your data, which may be structured as a dense graph of objects in the computer’s memory, becomes a linear sequence—or a series—of bytes. Such a linear representation is perfect to transmit or store. Raw bytes are universally understood by various programming languages, operating systems, and hardware architectures, making it possible to exchange data between otherwise incompatible systems.
When you visit an online store using your web browser, chances are it runs a piece of JavaScript code in the background to communicate with a back-end system. That back end might be implemented in Flask, Django, or FastAPI, which are Python web frameworks. Because JavaScript and Python are two different languages with distinct syntax and data types, they must share information using an interchange format that both sides can understand.
In other words, parties on opposite ends of a digital conversation may deserialize the same piece of information into wildly different internal representations due to their technical constraints and specifications. However, it would still be the same information from a semantic point of view.
Tools like Node.js make it possible to run JavaScript on the back end, including isomorphic JavaScript that can run on both the client and the server in an unmodified form. This eliminates language discrepancies altogether but doesn’t address more subtle nuances, such as big-endian vs little-endian differences in hardware.
Other than that, transporting data from one machine to another still requires converting it into a network-friendly format. Specifically, the format should allow the sender to partition and put the data into network packets, which the receiving machine can later correctly reassemble. Network protocols are fairly low-level, so they deal with streams of bytes rather than high-level data types.
Depending on your use case, you’ll want to pick a data serialization format that offers the best trade-off between its pros and cons. In the next section, you’ll learn about various categories of data formats used in serialization. If you already have prior knowledge about these formats and would like to explore their respective scenarios, then feel free to skip the basic introduction coming up next.
Compare Data Serialization Formats
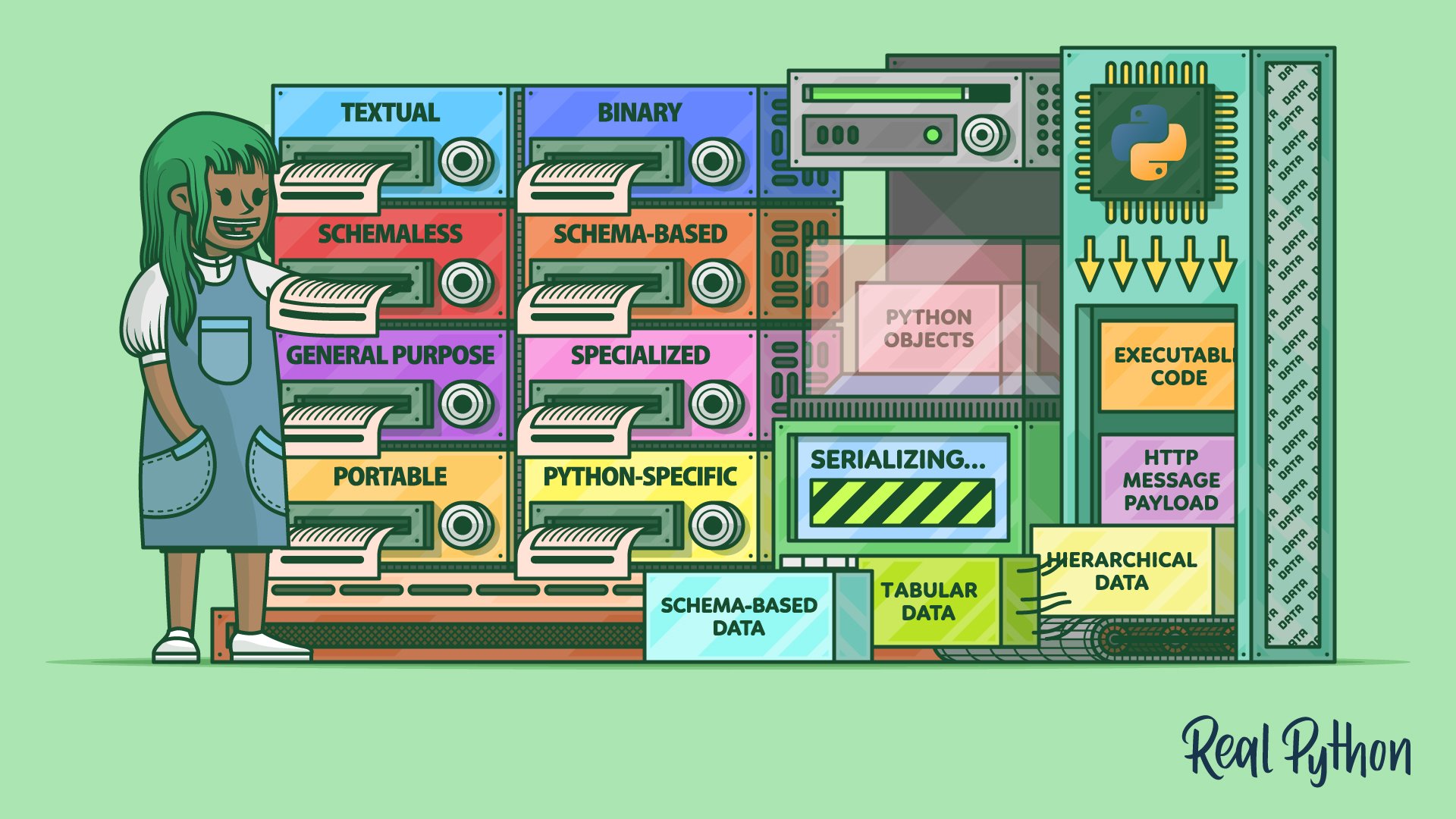
There are many ways to classify data serialization formats. Some of these categories aren’t mutually exclusive, making certain formats fall under a few of them simultaneously. In this section, you’ll find an overview of the different categories, their trade-offs, and use cases, as well as examples of popular data serialization formats.
Later, you’ll get your hands on some practical applications of these data serialization formats under different programming scenarios. To follow along, download the sample code mentioned in the introduction and install the required dependencies from the included requirements.txt file into an active virtual environment by issuing the following command:
(venv) $ python -m pip install -r requirements.txt
This will install several third-party libraries, frameworks, and tools that will allow you to navigate through the remaining part of this tutorial smoothly.
Textual vs Binary
At the end of the day, all serialized data becomes a stream of bytes regardless of its original shape or form. But some byte values—or their specific arrangement—may correspond to Unicode code points with a meaningful and human-readable representation. Data serialization formats whose syntax consists purely of characters visible to the naked eye are called textual data formats, as opposed to binary data formats meant for machines to read.
The main benefit of a textual data format is that people like you can read serialized messages, make sense of them, and even edit them by hand when needed. In many cases, these data formats are self-explanatory, with descriptive element or attribute names. For example, take a look at this excerpt from the Real Python web feed with information about the latest tutorials and courses published:
<?xml version="1.0" encoding="utf-8"?>
<feed xmlns="http://www.w3.org/2005/Atom">
<title>Real Python</title>
<link href="https://realpython.com/atom.xml" rel="self"/>
<link href="https://realpython.com/"/>
<updated>2023-09-15T12:00:00+00:00</updated>
<id>https://realpython.com/</id>
<author>
<name>Real Python</name>
</author>
<entry>
<title>Bypassing the GIL for Parallel Processing in Python</title>
<id>https://realpython.com/python-parallel-processing/</id>
<link href="https://realpython.com/python-parallel-processing/"/>
<updated>2023-09-13T14:00:00+00:00</updated>
<summary>In this tutorial, you'll take a deep dive (...)</summary>
<content type="html">
<div><p>Unlocking Python's true potential (...)
</content>
</entry>
(...)
</feed>
The Real Python feed uses the XML-based Atom Syndication Format, which is a form of a data serialization format. You can open the document above in any text editor without needing specialized software or libraries. Furthermore, just by looking at this feed, you can immediately break down its structure and probably guess the meaning of the individual elements without checking the format’s specification.
Now, compare the text-based Atom feed above with an equivalent binary feed. You can generate one by parsing atom.xml with xmltodict and dumping the resulting dictionary to a file using MongoDB’s BSON format. When you do, the result will look something like this:
$ hexdump -C atom.bson | head
00000000 51 d2 01 00 03 66 65 65 64 00 46 d2 01 00 02 40 |Q....feed.F....@|
00000010 78 6d 6c 6e 73 00 1c 00 00 00 68 74 74 70 3a 2f |xmlns.....http:/|
00000020 2f 77 77 77 2e 77 33 2e 6f 72 67 2f 32 30 30 35 |/www.w3.org/2005|
00000030 2f 41 74 6f 6d 00 02 74 69 74 6c 65 00 0c 00 00 |/Atom..title....|
00000040 00 52 65 61 6c 20 50 79 74 68 6f 6e 00 04 6c 69 |.Real Python..li|
00000050 6e 6b 00 72 00 00 00 03 30 00 3f 00 00 00 02 40 |nk.r....0.?....@|
00000060 68 72 65 66 00 20 00 00 00 68 74 74 70 73 3a 2f |href. ...https:/|
00000070 2f 72 65 61 6c 70 79 74 68 6f 6e 2e 63 6f 6d 2f |/realpython.com/|
00000080 61 74 6f 6d 2e 78 6d 6c 00 02 40 72 65 6c 00 05 |atom.xml..@rel..|
00000090 00 00 00 73 65 6c 66 00 00 03 31 00 28 00 00 00 |...self...1.(...|
In this case, you use the command-line tool hexdump to view the contents of your binary file, but it’s rather difficult to understand. While there are bits of text here and there, much of the data looks like gibberish.
Another great advantage of a textual data format is that text has a uniform and mostly unambiguous interpretation. As long as you know the correct character encoding, which is almost always the ubiquitous UTF-8 these days, then you’ll be able to read your serialized messages everywhere on any hardware and system imaginable. No wonder so many popular serialization formats like XML, JSON, YAML, and CSV are all based on text.
Note: As a Python programmer, you might be accustomed to using TOML for your project’s metadata in the pyproject.toml file. Build systems like setuptools and Poetry know how to read this file to build your Python package before you can publish it on PyPI.
While there’s some resemblance to other text-based formats, TOML is different. It’s not a data serialization format, primarily due to its rigid syntax and limited data types. Instead, TOML advertises itself as a configuration file format based on INI files, intended to make editing the configuration easier for humans.
Unfortunately, there’s no rose without a thorn. Text-based data serialization formats are slower to process than their binary counterparts because text has to be translated to native data types. They also use the available space less efficiently, which can limit their usefulness in larger datasets. Therefore, textual formats aren’t as common in data science and other fields that have to deal with big data.
Moreover, textual formats tend to become overly verbose and may contain a lot of redundant boilerplate. Notice how each element in the Atom feed above, such as the author of the feed, is wrapped in at least one pair of opening and closing XML tags, adding to the bloat. You can try compressing the serialized data to mitigate that, but it’ll add some overhead without providing predictable message sizes.
If you’re able to describe your data using plain English, then a textual data format is all you need. But what if you need to mix both text and binary assets in one text message? It’s possible. After all, email uses a text-based protocol, yet it lets you include binary attachments like pictures or PDF documents.
Embedding binary data in a text-based format requires expressing arbitrary bytes using a limited number of characters. One such technique involves Base64 encoding, which turns bytes into ASCII characters. The downside is that it increases the size of the binary asset by about thirty percent. So, sharing your vacation photos with colleagues at work through email can quickly bring your department’s network down!
Note: A common work-around to this problem is to strip the message from binary assets, send them separately using a different communication channel, and only include their handles in the serialized text.
For example, some email providers implement this feature behind the scenes by uploading binary assets to the cloud while linking to them in your message. The same is true for many web APIs, whose responses include hyperlinks to files stored elsewhere instead of directly embedding them in the serialized message.
There’s also the issue of security risks associated with leaking sensitive information due to the ease of reading textual data formats. In contrast, making sense of a message serialized to a binary data format is more challenging but certainly not impossible. Therefore, serializing private information like passwords or credit card numbers always requires strong encryption regardless of the data format!
To sum up, here’s how textual and binary data formats stack up against each other:
| Textual | Binary | |
|---|---|---|
| Examples | CSV, JSON, XML, YAML | Avro, BSON, Parquet, Protocol Buffers |
| Readability | Human and machine-readable | Machine-readable |
| Processing Speed | Slow with bigger datasets | Fast |
| Size | Large due to wasteful verbosity and redundancy | Compact |
| Portability | High | May require extra care to ensure platform-independence |
| Structure | Fixed or evolving, often self-documenting | Usually fixed, which must be agreed on beforehand |
| Types of Data | Mostly text, less efficient when embedding binary data | Text or binary data |
| Privacy and Security | Exposes sensitive information | Makes it more difficult to extract information, but not completely immune |
With this table, you can understand the key differences between textual and binary data serialization formats before deciding which one fits your specific needs. Once you know the answer, the next question should be whether to use a schema or not.
Schemaless vs Schema-Based
Regardless of whether they’re textual or binary, many data serialization formats require a schema document, which is a formal description of the expected structure of serialized data. At the same time, some formats are schemaless, while others can work with or without a schema:
| Schemaless | Schema-Based | |
|---|---|---|
| Textual | JSON, XML, YAML | JSON+JSON Schema, XML+XML Schema (XSD), XML+Document Type Definition (DTD) |
| Binary | BSON, pickle | Avro, Protocol Buffers |
Depending on the format at hand, you can express the corresponding schema differently. For example, it’s common to provide an XML-based XSD schema for XML documents, while the binary Avro format relies on JSON for its schemas. Protocol Buffers use their own interface definition language (IDL), on the other hand.
The schema for the Atom feed that you saw earlier leverages a somewhat dated RELAX NG format, which stands for regular language for XML next generation. Unlike the more widespread XML Schema (XSD), it’s not based on XML itself:
# -*- rnc -*-
# RELAX NG Compact Syntax Grammar for the
# Atom Format Specification Version 11
namespace atom = "http://www.w3.org/2005/Atom"
namespace xhtml = "http://www.w3.org/1999/xhtml"
namespace s = "http://www.ascc.net/xml/schematron"
namespace local = ""
start = atomFeed | atomEntry
# Common attributes
atomCommonAttributes =
attribute xml:base { atomUri }?,
attribute xml:lang { atomLanguageTag }?,
undefinedAttribute*
# ...
A schema typically defines the allowed set of elements and attributes, their arrangement, relationships, and the associated constraints, such as whether an element is required or what range of values it can take. You can think of it as the vocabulary and grammar of a data serialization language.
This concept is analogous to a relational database schema, which specifies the tables, their column types, foreign keys, and so on. It’s a blueprint for re-creating the database from scratch, which can also act as a form of documentation. At runtime, the database schema governs your data’s referential integrity. Lastly, it helps facilitate object-relational mapping (ORM) in frameworks like Django.
Note: Within the realm of web services, two popular technologies that rely heavily on data serialization schemas are SOAP and WSDL. These days, however, modern alternatives like GraphQL, REST combined with JSON, and gRPC have mostly superseded them.
The benefits of using a schema in a data serialization format include:
- Automation: The formal specification of data allows you to generate code stubs in different programming languages to handle automatic serialization and deserialization of each language’s native data types. This is also known as data binding when you use the XML format.
- Consistency: The schema enforces a standard structure for serialized data, ensuring its integrity and consistency across different systems.
- Documentation: The schema provides a clear definition of the structure of the data, which can help you quickly understand how the information is organized.
- Efficiency: Referencing the schema instead of including explicit field names reduces the size of serialized data. The schema can be known ahead of time or be embedded in the serialized message.
- Interoperability: Sharing the schema between different applications or services can facilitate their integration by allowing them to communicate with each other.
- Validation: The schema can be used to validate serialized data in an automated way, catching potential errors early on.
While there are many benefits to employing a schema, it also comes with some drawbacks, which you should weigh before deciding whether or not to use one. The highest price to pay for adopting a schema is the limited flexibility of the serialized data. The schema enforces a rigid structure, which may not be desirable if your data evolves over time or is dynamic in the sense that it doesn’t have a fixed layout.
Moreover, it can be difficult to alter a schema once you commit to one. Even though some schema-based formats, such as Avro, allow for schema versioning, this may generally break the consistency of data that you previously serialized. To mitigate this problem, some tools in the relational database domain offer schema migration, which gradually transforms data from an old schema to a new one.
For rapid prototyping or when working with unstructured data with unpredictable layouts, a schemaless data serialization format may be more suitable. Conceptually, this is like having a NoSQL database that can accept and process data from multiple sources. New types of elements or unknown attributes would be ignored without breaking the system instead of failing the schema validation.
All in all, these are the most important pros and cons of schemaless and schema-based data serialization formats:
| Schemaless | Schema-Based | |
|---|---|---|
| Flexibility | High | Can’t handle unstructured data or easily modify its shape |
| Consistency | Data integrity can become a problem | High |
| Size | Large due to repetitive inclusion of metadata | Compact, especially when the schema is separate |
| Efficiency | Fast storage, slow lookup | Querying the data is fast thanks to its uniform structure |
| Simplicity | Straightforward to implement | Requires more effort and planning up front |
All right, you’ve successfully narrowed down your options regarding the numerous types of data serialization formats. You’ve determined whether choosing a binary format over a textual one is more suitable in your case. Additionally, you understand when to use a schema-based format. Nonetheless, there are still a few choices left on the table, so you must ask yourself some more questions.
General-Purpose vs Specialized
Some data serialization formats are expressive enough to represent arbitrary data, making them universal formats. For example, JSON has become the prevailing data serialization format, especially in web development and REST API design. This format has a minimalistic syntax with only a few essential building blocks that are straightforward to map onto numerous data types in the vast landscape of programming languages.
Note: In the past, the ubiquitous XML format played a similar role but lost its popularity due to the sudden rise of JSON. The biggest argument for using JSON was its cheap deserialization cost on the client side, thanks to being modeled after JavaScript literals. Moreover, people started using XML for purposes that it wasn’t designed for, which led to a growing dislike and a reputation for being notoriously problematic.
On the opposite end of the spectrum, you’ll find specialized formats that can only represent a particular type of data. For example, XML continues to be an excellent format for describing deeply nested hierarchical data like user interfaces. After all, XML belongs to the same family of markup languages as HTML, which is widely used to structure content on the Internet.
Another example of a specialized data serialization format is the comma-separated values (CSV) format. It works best with flat tabular data like spreadsheets, database tables, or DataFrames. While you might be able to serialize a data record by mapping its attributes to table columns, modeling hierarchical data with CSV is less convenient than with XML. But, as a textual format, CSV can reach its limits even when handling tabular data.
Note: When researching data formats, you may come across an alternative nomenclature. Some people refer to tabular data formats as flat, while they call hierarchical formats structured.
In data science, you often have to process enormous amounts of data. To optimize performance and reduce storage costs, it’s usually preferable to choose a binary data serialization format dedicated to such large datasets.
These days, Parquet and Feather are gaining popularity in the data science space. They’re both compatible with Arrow, which is an in-memory specification that allows data-sharing between different libraries and even different programming languages. A couple of older but still popular ones are HDF5 and NetCDF. Their newer counterpart, Zarr, offers better support for distributed data storage and computation.
Special data serialization formats emerged in other domains, as well. Some examples include the following:
- DICOM: A binary format for storing and transmitting medical images
- GeoJSON: A specialized flavor of JSON for serializing geographic features
- GPX: An XML-based format for exchanging GPS coordinates
- MusicXML: An XML-based format for storing musical notation
- OBJ: A textual format for storing three-dimensional models
Whether you can use a textual or binary format, with or without a schema, may actually depend on your use case. Some specialized data serialization formats give you little choice in that regard. But there’s one final question that you must ask yourself before choosing the right data serialization format for you. You’ll read about it in the next section.
Portable vs Python-Specific
Another criterion to consider when choosing a data serialization format for your use case is where you’re going to use it. If you wish to exchange information between foreign systems, then opt for a popular data serialization format that’s globally understood. For example, JSON and Protocol Buffers are widely adopted across different programming languages and platforms.
On the other hand, if you only intend to serialize and deserialize data within Python, then you may choose a Python-specific format for practicality reasons. It’ll be a more efficient and convenient option, provided that you’re not planning to share the serialized data with other systems.
Python ships with the following modules in the standard library, which provide binary data serialization formats for different purposes: